
?作者 | 小欣
目标检测一直是计算机视觉的热门领域,它也具有丰富的应用场景,从无人驾驶到缺陷检测等等。
在YOLO诞生之前,目标检测领域热门的深度学习模型是R-CNN系列模型,这一类的模型被称之为二阶段模型(two-stage),其大致思路就是先找出可能含有物体的区域,进而再细致的找出这片区域内的物体是什么,在哪个位置。
这一类模型的特点就是准确率较高,但是速度较慢,难以做到实时检测。而这时候,YOLO V1应运而生,它的特点就是速度快,在牺牲部分模型性能的情况下,能做到实时检测。
YOLO直接从图片中去寻找可能存在物体的位置,因此也被称为单阶段模型(one-stage) 。
要想透彻了解YOLO系列模型的运行原理,需要从V1版本开始讲起,看作者如何迭代更新,一步步改良YOLO,在这个学习过程中,也能学到很多相关的目标检测知识。
YOLO V1
01 思路
YOLO V1发表在2016年,其作者是Joseph Redmon。YOLO V1的想法很朴素,但也很有效。
简单地说,它将一张图分成个网格,假设,即它将一张图分成了49个网格,不难想象,原图中每个物体的中心都在其中一个网格中。
因此,只需要让每个网格负责预测中心点落在当前网格中的物体。这在训练的时候是很容易办到的,因为我们已知每个物体的坐标。
通过这样的思想,作者构建出了一个端对端、且非常高效的模型,并在其基础上,不断进行改进,提出了后续的V2,V3等。
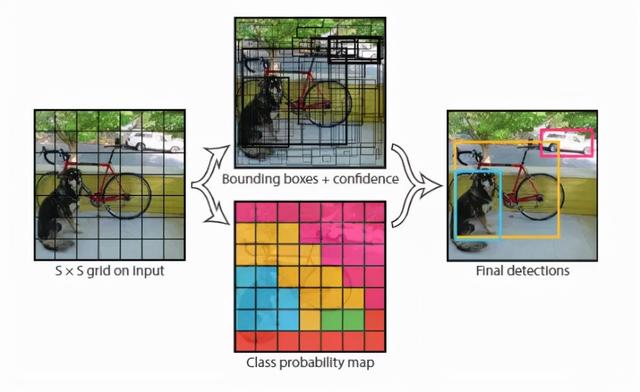
如下图所示,只需要三步,YOLO就可以得到较好的预测结果。


02 网络设计
接下来我们开始详细介绍YOLO V1的流程。首先,对于任意一张图片,YOLO首先将它resize成448X448大小的尺寸,将其传入CNN模型中,进行提取特征,其具体结构如下图所示,这里假设每个网格都配备两个预测框,也就是每个网格需要预测两个bbox。
内部网络结构类似于VGGNet,比较简单,包含卷积层,下采样层等,直到最后一步,得到一个7X7X1024的特征图。
可以想象,该特征图一个像素,应该包含了原图较大范围内的信息,这时将最后的特征图拉直变成一维向量,通过全连接层将维度依次降为4094,1470维,将最后的1470维的一维向量reshape成7X7X30,即为最后的输出。

我们最后得到的7X7X30输出,是和下图左边的网格图对应的,每一个网格对应一个1X1X30的输出。
这个1X1X30的输出同样有学问,它的前面十个数值对应两个预测框的中心点坐标,长,宽和置信度(x,y,h,w,conf),因为我们前面假设的是一个网格配置两个预测框,所以有10个数值,如果配置更多的话,相应的维度也会增加。
而它的后20个值对应的是类别概率,假设我们这边预 测总共有20个类别,但是这样的做法,实际上也是YOLO V1的缺点,因为一个网格它实际上只能预测一个物体,它的类别由输出的后20个通道决定,bbox由前10个通道中的置信度高的bbox决定。
如果输入图是一张有小目标的图像,一个网格有若干个物体,那YOLO V1只能找出网格中的一个,这一点会在后面的版本进行改进。
另外值得一提的是,YOLO中的bbox的格式是(x,y,w,h),也就是给bbox的中心点坐标和长宽,为了方便训练,这四个值都是要做标准化处理,也就是除以原图的尺寸,它们的取值都是在0~1之间。
还需要注意的是,模型给出的输出(x,y)是相对于所在网格左上角坐标的偏移量,它的值在0~1之间,所以我们得到的(x,y)的坐标还要加上网格左上角坐标才是真正的bbox的坐标位置,至于bbox的长宽,也是在0~1之间的,但它们就不是偏移量了,是直接预测得到的,这种方式也被称为anchor-free方法,即不需要预先给定bbox的尺寸。
这一点在R-CNN系列中不是这样的,R-CNN系列中,学到的(x,y,w,h)都是偏移量,它们是由先验框进行指导的,事实上这也是YOLO V2的改进之一,凭空生成的anchor不如有先验知识的anchor准确,这在之后的版本中也进行了改进。
03 损失函数
要想知道YOLO V1是怎么学习的,还需要知道它的损失函数是怎么设计的,了解V1的损失函数,有助于了解后面的YOLO系列。

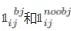
分别代表网格内有无物体时的示性函数,损失函数的第一项相当于做的是对bbox的中心点坐标的平方误差,容易理解。
而第二项是bbox的长宽,它是相当于做了开根之后在进行计算平方误差,之所以这么做是为了让小目标的物体的长宽预测更准一些,假设长宽的误差是0.1,对大物体来说可能不值一提,但是对于小物体来说,可能这个误差就比较致命了,对于0-1之间的数值做开根运算,得到的数值是会变大的,有助于预测。
第三项和第四项针对的是不同框的置信度,因为YOLO V1中,一个网格只预测一个物体,所以置信度高的被认为含有物体,低的被预测为不含物体。
另外需要注意的是,这两项前面有一个系数

前者取5,后者取0.5,因为我们更关注有物体的bbox,但也不能完全忽视不含物体的bbox;而最后一项是计算当前网格所属类别的,实际上也能使用交叉熵,但是作者为了建立一个统一的框架,采用了回归的计算方法,这样整个损失函数都是回归形式的,更加的和谐统一。
04 置信度介绍
在前面笔者提到了若干次置信度的概念,这一概念直观上给人的感受是可信度或者概率,实际上它包含的信息更丰富,在这里进行具体的讲解。
置信度包含两方面的含义,一个是bbox含有目标的可能性,另一个是这个bbox的准确率,
前者我们将其记为
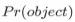
当边界框包含物体时,

不包含时则为0;
bbox的准确度可以用IOU这一指标进行表示,记为

因此置信度可以定义为
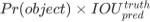
在训练时,对于不含物体的bbox,它们的置信度就0,反之则为1,然后与预测的置信度一起计算loss;
在测试阶段,置信度是直接生成的,可以理解成已知该区域有物体的条件下,是何类别的概率。
05 网络预测
以上介绍了模型的流程,实际上也介绍了它的训练过程,接下来再介绍它的测试流程。
测试流程与训练流程有一些不一样,因为此时我们不知道哪些网格中有物体,对于输出的bbox,我们需要采用NMS的算法删除冗余的bbox,留下正确的bbox。
NMS算法的流程如下:首先从所有的检测框中找到置信度 最大的那个框,然后挨个计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框。
我们来介绍它是怎么使用NMS算法的。
因为我们对一个网格要预测两个bbox,所以最后我们能得到个7X7X2=98个bbox。
首先,将这 98个bbox中置信度低的框去掉,然后再根据置信度对剩下的bbox排序,使用NMS算法,把重复度高的框的置信度设为0。
对于留下的框,再根据分类概率得到它们的类别,这里注意得到的框的大小都是相对于原图大小的,都是0-1之间的值,所以输出的时候还需要还原,才能得到真实的bbox的尺寸大小。
06 模型缺点
● 使用全连接层,参数量巨大,而且也因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。
● 一个网格只能预测一个物体。
● anchor-free的方法没有anchor-based的准确。
● 对小目标物体的检测能力有限,且物体检测的定位准确性较低。
以上其实也是YOLO V2的改进之处。
参考资料
[1] https://zhuanlan.zhihu.com/p/32525231
[2] https://arxiv.org/abs/1506.02640
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。

如若转载,请注明出处:https://www.gooyie.com/31714.html
相关推荐
-
京东买二手苹果可靠吗,苹果建议买二手还是新机?
近年来,二手交易平台越来越普及,不少人选择在这里购买二手设备,更是有不少人选择在京东上购买二手苹果。但是,这些二手设备真的可靠吗?苹果公司建议我们购买二手还是新机呢?本文将通过调查…
-
拼多多无货源开店真的赚钱吗,快手拼多多无货源开店真的赚钱吗?
在如今电商行业的蓬勃发展中,拼多多作为一个相对年轻的电商平台,吸引了无数创业者的目光。然而,有关拼多多无货源开店是否真的能够赚钱的争议一直存在,并且近来快手拼多多无货源开店的话题也…
-
网络规划设计师论文(网络规划设计师报考条件)
公司简介 九米设计根植于本土,是一所具有建筑工程甲级资质的设计公司。2009年成立于杭州,发展至今已有设计人员200余名,落成项目遍布于全国25个城市与乡村,类型包括高端公寓、别墅…
-
京东地区消费券怎么领,京东地区消费券怎么领取?
京东地区消费券是京东专门为各地区推出的一种优惠券,用户可以在京东上使用消费券享受相应的优惠。那么,如何领取京东地区消费券呢?下面,我们将详细介绍。 首先,要领取京东地区消费券,需要…
-
朋友圈集赞文案,朋友圈集赞文案范文?
朋友圈集赞文案范文 随着社交网络的发展,朋友圈已经成为了现代人生活中的一个重要组成部分。我们每天都会不自觉地打开朋友圈,浏览朋友们的动态,同时也会分享自己的生活点滴。然而,随着朋友…
-
手机推广平台,手机推广平台有哪些_?
手机推广平台,了解这些常见的手机推广平台 现如今,手机已经成为了人们生活中不可或缺的一部分。随着智能手机的普及,越来越多的企业意识到了手机推广的重要性。手机推广平台应运而生,为企业…
-
社会化媒体营销,社会化媒体营销的特点?
一、什么是社会化媒体营销? 社会化媒体营销,也叫社交媒体营销,是通过社交媒体平台进行产品或服务推广的一种营销方式。它不同于传统的广告营销方式,不是通过付费广告的形式来推销产品,而是…
-
项链上jy是什么意思_(男人的jy是什么意思_)
如何判断报恩的价值 吾年数省吾身,大家好,我是“召吾”大叔!上次我们站在施恩方的角度讲了施恩不图报,因为双方对施恩和报恩的价值有不同看法,今天我们继续作为施恩方来探讨如何判断别人报…
-
微信公众号封面图尺寸,公众号封面图尺寸?
近年来,随着自媒体的发展,越来越多的人将其当成主业或者副业。并吃到了自媒体发展的红利,甚至一部分人通过自媒体实现了财富自由。 有人说公众号的红利期早就过了,其实对于底部创业者来说,…
-
数字藏品行业迎自律发展倡议_蚂蚁、腾讯、百度、京东等联合发起
新京报贝壳财经讯(记者潘亦纯 罗亦丹)数字藏品正以前所未有的热度引发广泛关注,但部分缺乏风险管控的平台引发局部乱象也开始显现。 6月30日,在中国文化产业协会的牵头下,近30家机构…